
یکی از سوالاتی که برای بعضی از دوستان پیش می آید این است که آیا ترتیب تعریف ستون های یک جدول تاثیری بر عملکرد کوئری ها دارد؟
برای پاسخ به این سوال، به نحوه ذخیره سازی سطرهای جداول در یک block توجه فرمایید که به شکل زیر است:
Dn |
Ln |
… |
D3 |
L3 |
D2 |
L2 |
D1 |
L1 |
H |
H: Header
Ln: Length of Column n
Dn: Data of Column n
این نکات را در نظر داشته باشید:
پس با توجه به موارد بالا، در طراحی جدول این نکات را در نظر داشته باشید:
حالا نگاهی هم به هزینه اجرای دستورات می اندازیم. برای این کار جدول test_cost_tbl را با پنج ستون می سازیم:
drop table test_cost_tbl purge;
CREATE TABLE test_cost_tbl(
col_1 NUMBER,
col_2 NUMBER,
col_3 NUMBER,
col_4 NUMBER,
col_5 NUMBER);
سپس یک سطر در این جدول insert و آمار جدول را نیز بروز رسانی میکنیم:
INSERT INTO test_cost_tbl VALUES (1, 2, 3, 4, 5); commit; begin dbms_stats.gather_table_stats(user,'test_cost_tbl'); end;
برای خواندن هر کدام از ستون های جدول به صورت مجزا و تهیه Plan اجرای آنها از دستورات زیر استفاده می کنیم:
EXPLAIN PLAN SET STATEMENT_ID 'col_1' FOR SELECT col_1 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_2' FOR SELECT col_2 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_3' FOR SELECT col_3 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_4' FOR SELECT col_4 FROM test_cost_tbl; EXPLAIN PLAN SET STATEMENT_ID 'col_5' FOR SELECT col_5 FROM test_cost_tbl;
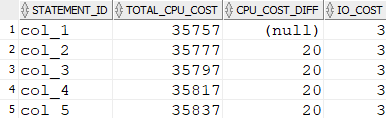
با بررسی مقادیر ثبت شده در جدول plan_table می توانیم مشاهده کنیم که هزینه CPU خواندن از ستون ها با هم متفاوت است (20 عدد به ازا هر ستون به هزینه CPU اضافه می شود) اما هزینه I/O آنها ثابت مانده است. علت ثابت ماندن هزینه I/O احتمالاً این است که کل رکورد در یک بلاک ذخیره شده اند و برای خواندن آن نیاز به I/O اضافی نیست.
SELECT statement_id, cpu_cost as total_cpu_cost,cpu_cost-lag(cpu_cost) OVER (ORDER BY statement_id) AS cpu_cost_diff, io_cost FROM plan_table WHERE id = 0 ORDER BY statement_id;
خروجی دستور بالا به شکل تصویر زیر قابل مشاهده است:
پی نوشت:
این مطلب و مثال را چند سال پیش از یک وبلاگ خواندم و مستند کردم. متاسفانه آن وبلاگ را پیدا نکردم تا ارجاع بدهم که در این مورد عذرخواهی میکنم.
موفق باشید
به اطلاع میرسانم موسسه آموزشی آکادمی عصر اوراکل
با مدیریت آموزشی اینجانب حمیدرضا قاسمی از ابتدای سال 1398 آغاز بکار
کرده است. علاقه مندان میتوانند جهت اطلاع از دوره های آموزشی آکادمی عصر
اوراکل به وبسایت AsreOracle.com مراجعه و یا با شماره تلفن 86084023 تماس حاصل نمایند.
دوره های قابل ارائه در آکادمی عصر اوراکل به شرح زیر میباشد:
توسعه برنامه های کاربردی
| نام دوره | مدت دوره (ساعت) | مدرس |
|
Oracle Database 18c: Introduction to SQL |
40 | مهندس رستنده |
| Oracle Database 12c Program with PL/SQL | 40 | مهندس رستنده |
| Oracle Database: SQL Tuning for Developers> | 16 | مهندس رستنده |
| Oracle Application Express Workshop I | 32 | -- |
| Oracle Application Express Workshop II | 32 | -- |
پایگاه داده Oracle 18c
| نام دوره | مدت دوره بر ساعت | مدرس |
| Oracle Database 18c: Admin, Install and upgrade Accelerated | 48 | مهندس رستنده |
| Oracle Database 18c: Data Guard Administration | 32 | مهندس رستنده/مهندس قاسمی |
| Oracle Database 18c: RAC and Grid Infrastructure Administration | 32 | مهندس رستنده/قاسمی |
| Oracle Database 18c: Security | 32 | مهندس رستنده |
| Oracle Database 18c: Performance Tuning | 24 | مهندس رستنده |
| Oracle Database 18c: New features | 32 | مهندس رستنده |
| Oracle Database 18c: Managing Multitenant | 24 | مهندس رستنده |
هوش تجاری و انبارداده اوراکل
| نام دوره | مدت دوره بر ساعت | مدرس |
| Data Warehouse Fundamentals | 16 | مهندس قاسمی |
| Oracle Data Integrator 12c | 40 | مهندس قاسمی |
| Oracle Business Inteligence 12c: Create Dashboard & Build Repository | 56 | مهندس قاسمی |
| Oracle Golden Gate 18c | 24 | مهندس قاسمی |
| Oracle Data Warehouse Performance Tuning | 8 | مهندس قاسمی |
| Oracle Business Intelligence 12c: Special Features | 12 | مهندس قاسمی |
علم داده (داده کاوی و بیگ دیتا)
| نام دوره | مدت دوره بر ساعت | مدرس |
| Data Mining Concepts & Techniques with R | 40 | دکتر عشقی |
| Python Standard | 40 | مهندس سهامی |
| Machine learning with Python | 40 | مهندس سهامی |
| Hadoop Big Data Fundamentals | 40 | مهندس نادری |
سیستم عامل لینوکس
| نام دوره | مدت دوره بر ساعت | مدرس |
| Linux 7.x For Data Engineers | 40 | مهندس ثابتی مقدم |
| Linux 7.x Essentials and System Administration | 16 | مهندس ثابتی مقدم |
این قابلیت در نسخه 12.1.0.2 (Enterprise) اضافه شد. این قابلیت در واقع یک property برای جداول است و مشخص می کند که سطرها با چه ترتیبی و چگونه باید کنار هم (به صورت فیزیکی) بر اساس مقادیر یک یا چند ستون دسته بندی و ذحیره شوند.
(توجه کنید که این قابلیت با Table Cluster تفاوت دارد)
با این کار اطلاعاتی که به طور متناوب آنها را با هم می خواهیم در بلاک های پشت سر هم ذخیره می شوند و بنابراین باعث افزایش چشمگیر سرعت اجرای دستورات خواهیم بود.
ادامه مطلب
سلام
میخواهیم یک جدول را از یک اسکیما به اسکیمای دیگر کپی کنیم. مثلاً فرض کنید که جدول source_tbl را می خواهیم به جدول با نام target_tbl در اسکیمای دیگر منتقل کنیم. می دانیم که این کار به روش های متفاوتی قابل انجام است:
دو روش اول شناخته شده تر و متداول تر هستند اما روش سوم به ندرت استفاده می شود و خیلی ها از این ویژگی مطلع نیستند. با استفاده از این روش با سرعت بالا می توانید نسبت به جابجایی اطلاعات اقدام کنید. در اینجا می خواهم روش سوم را به شما دوستان نشان دهم.
ادامه مطلب
درباره این سایت